Traversing the Future
Although the community seems to be turning toward direct style Scala nowadays, I have to admit that I kinda like the functional constructs. Higher-kinded types, monads, IO, etc., are things that, in my opinion, make the code more explicit. Often, they highlight two important aspects of a robust application: calls that are asynchronous and calls that might fail.
Of course, you have to find a balance between the functional gibberish and the real logic. As always in programming, it’s a kind of art. I’ve never worked commercially on a project that is written in a purely functional way. All of them contained some Akka code or a Java library with side effects. The right word to describe these projects is “pragmatic” - we used tools to get things done, not to blindly follow some set of paradigm rules.
I blend pure and impure code on daily basis, which presents a unique set of challenges. In this post, I’ll delve into one of those challenges.

The context
I might be wrong, but I think that the impure class I use most frequently is the Future. It’s one of the basic building blocks of Akka and a natural wrapper around Java Futures. Scala provides various ways to manipulate Futures, including methods defined in the Future itself and for-comprehensions. However, when Options and Eithers come into play, things get more complicated. Manipulating Future[Either[DomainError, Result]] is not as straightforward as operating on Future[Result].
For this reason, I frequently use cats to simplify things. Although cats is designed to work with purely functional code, it also has interop with Futures. This interop allows us, for instance, to:
- Use
EitherT[Future, DomainError, Result]instead ofFuture[Either[DomainError, Result]] - Use
.voidinstead of.map(_ => ()) - Use
foo |+| barinstead offoo.flatMap(foo => bar.map(bar => foo + bar))
Of course, there is a whole host of other use cases. This post will be about .traverse and also a bit about .sequence.
This post aims to explain one of the reasons why using
Futures with cats is generally discouraged. While it often fits into “pragmatic” code, it might lead to unexpected behavior if used without extra caution.
Why is Future not pure?
Long story short, the problem with Future is that it’s evaluated eagerly. The moment a Future is defined, it immediately starts the computation. You might wonder if that’s a problem at all - it turns out it might be. Consider the following two snippets:
1
2
3
4
5
6
7
8
for {
_ <- Future(println("hello"))
_ <- Future(println("hello"))
} yield ()
// Output:
// hello
// hello
1
2
3
4
5
6
7
8
9
val hello = Future(println("hello"))
for {
_ <- hello
_ <- hello
} yield ()
// Output:
// hello
If Future was pure, the results would be the same. However, because of its eager evaluation, which breaks referential transparency, the results are different. If we used IO here instead, we would receive the same output.
Note that the problem isn’t about using
println, which has a side effect. Side effects, when correctly enclosed in anIO(or similar abstraction), are pure.
If you have to use a
Future, there is a way to wrap it with anIOto make it pure. See IO#fromFuture for more details.
What is a functional traversal?
Now, quickly about .traverse. To simplify the explanation, we’ll start with .sequence instead.
.sequence
Imagine that we have an element of type A. Let’s first wrap it with a G[_]. Then, wrap the result in an F[_]. Having F[G[A]], we want to flip the wrappers, receiving G[F[A]]. That’s exactly what .sequence does.
For instance, when our F[_] is a List, G[_] is an Option, and A is an Int:
1
2
3
4
5
6
import cats.implicits._
val foo = List(Some(1))
println(foo.sequence) // Some(List(1))
val bar = List(None)
println(bar.sequence) // None
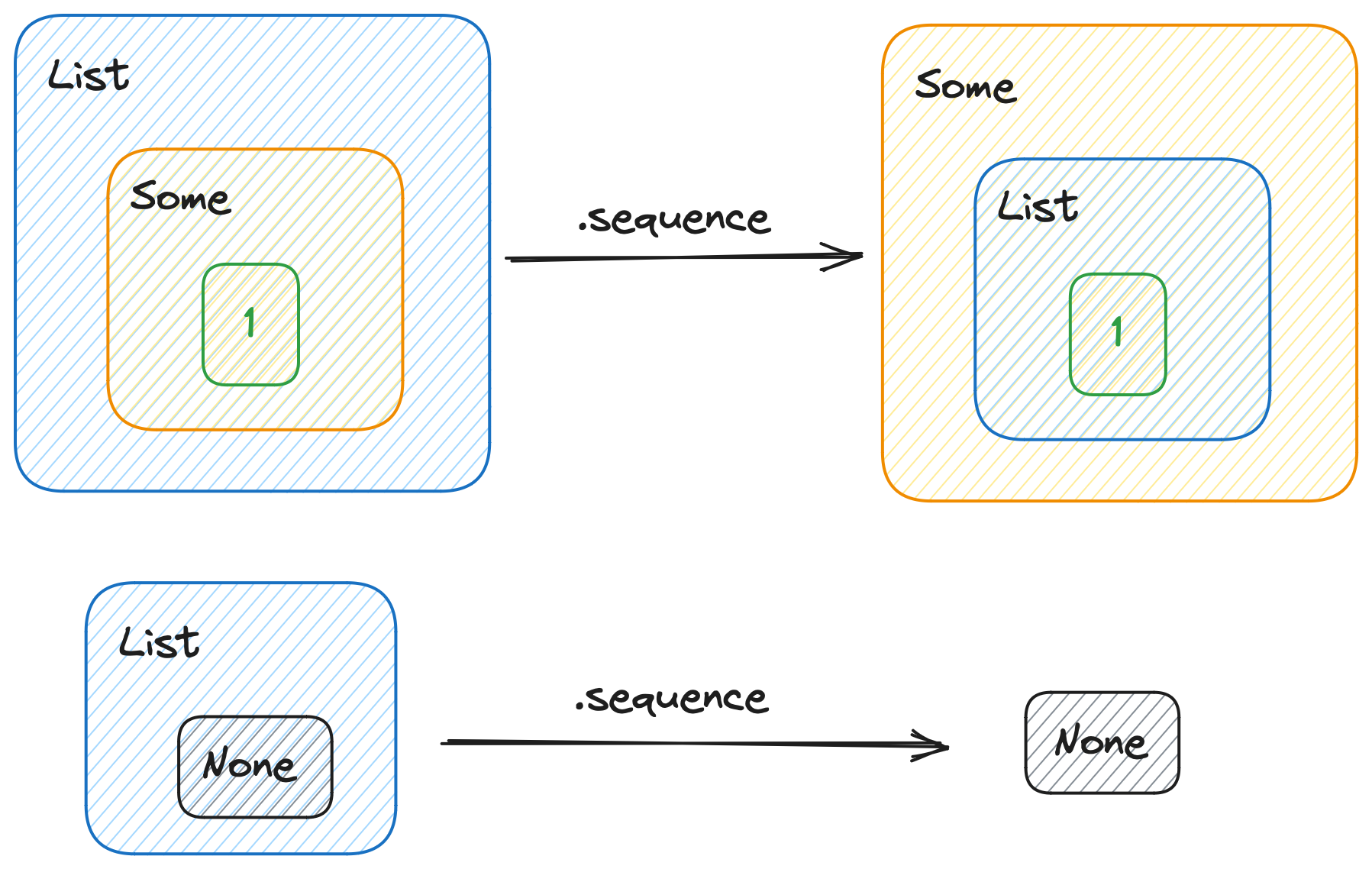 .sequence applied to a List[Option[Int]]
.sequence applied to a List[Option[Int]]
Note that this conversion is not always possible. Let’s say we have a Future and a List of Ints. We can sequence the operations one way:
1
List(Future(1), Future(2), Future(3)).sequence // yields a `Future[List[Int]]`
but not the other:
1
Future(List(1, 2, 3)).sequence // compilation error
This makes sense because if the second .sequence worked, we would be able, for instance, to tell the size of the list before the computation inside the Future was finished.
.traverse
Traversal goes one step further than .sequence by additionally converting A to B. Imagine that instead of having F[G[A]], we have an F[A] and a function A => G[B]. After we apply that function to A, we .sequence the result. That’s what .traverse does.
Moreover, .traverse can be implemented via .sequence. .traverse(f) is the same thing as .map(f).sequence.
Let’s see an example, analogous to the previous one:
1
2
3
4
5
6
import cats.implicits._
val foo = List("1")
println(foo.traverse(_.toIntOption)) // Some(List(1))
val bar = List("not an Int")
println(bar.traverse(_.toIntOption)) // None
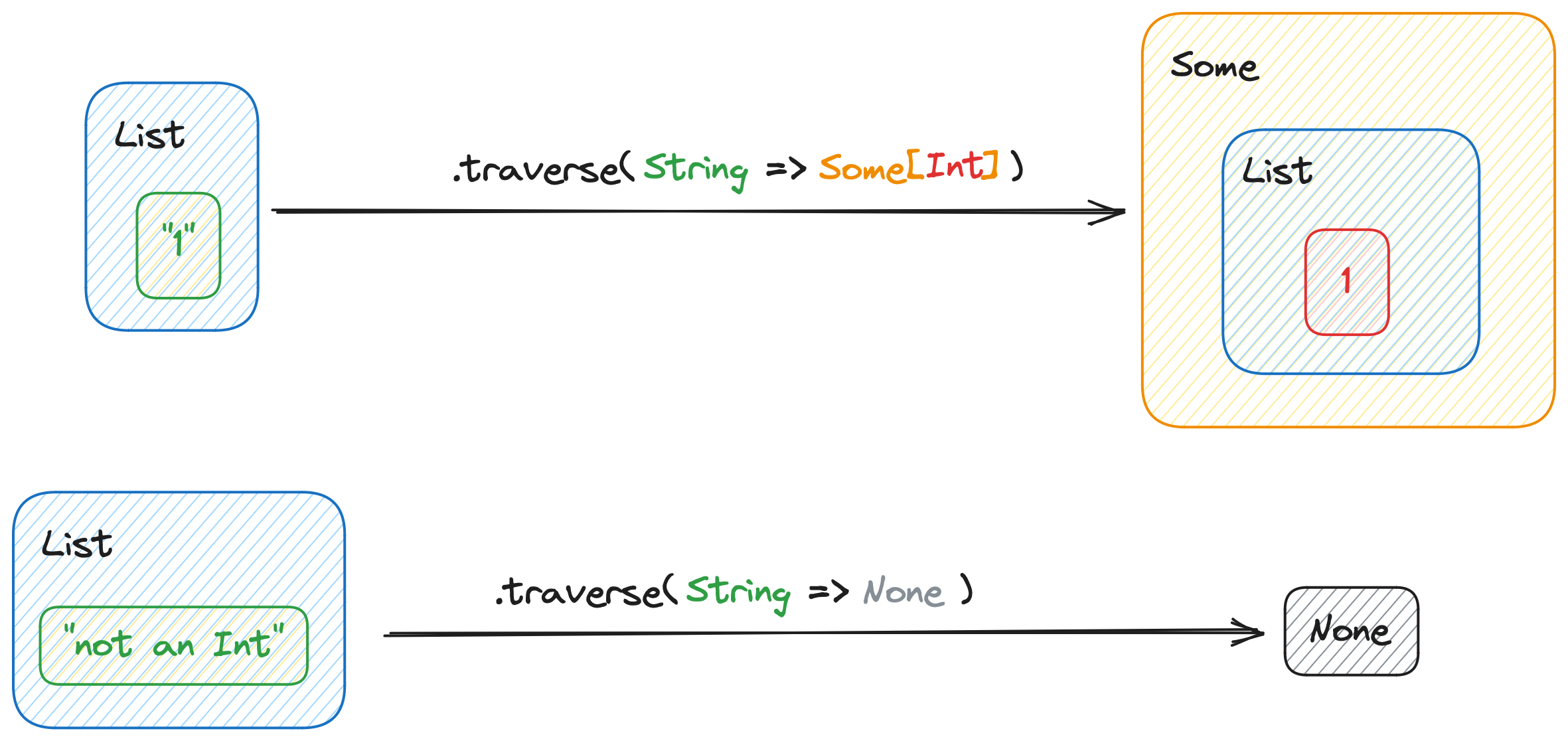 .traverse applied to a List[String] using a String => Option[Int] function
.traverse applied to a List[String] using a String => Option[Int] function
The challenge
I surprisingly find myself quite often in situations where I have to execute some asynchronous operation on every element of a collection. One example is legacy Java libraries that don’t execute operations in batches; another might be an external API that doesn’t expose endpoints for batch edits.
Here is the pattern:
- I have a collection of elements like
List[Entity]. - I also have a function that executes an asynchronous operation using
Entity(Entity => Future[Result]). - I want to execute that operation on each
Entityinstance, gettingList[Future[Result]]or something similar. - Then, to simplify things, I want to convert it into a
Future[List[Result]]or even a singleFuture[BatchResult]if I can combineResults somehow.
As you see, this perfectly fits what .traverse does. Let’s implement it then:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
type Entity = String
type Result = String
val entities = List("humongous", "blue", "fluffy", "monster") // 1
def heavyComputation(entity: Entity): Future[Result] = // 2
Future {
println(s"Converting [$entity]...")
val result = entity.toUpperCase
Thread.sleep(100 * entity.size) // Pretend it's really heavy
println(s"Converted [$entity] into [$result]")
result
}
def runCatsTraverse() = {
println("\ncats .traverse(f)")
val results = entities.traverse(heavyComputation) // 3
println(s"results = ${Await.result(results, 15.seconds)}")
}
Please forgive me for all the side effects and impurity of the code in the examples. I wanted to keep the examples as simple as possible to reduce the noise irrelevant to the actual problem.
In the snippet above, we have a list of entities (1) and a simulated heavy computation (2). Now, for we traverse each element in the list, getting a list of results (3).
Speaking in terms of types, we have a List[Entity] (1) and a function Entity => Future[Result] (2) that we use for traversal to ultimately receive Future[List[Result]] (3).
We are passing the list [humongous, blue, fluffy, monster] as the input and expect a parallel conversion to uppercase, resulting in [HUMONGOUS, BLUE, FLUFFY, MONSTER] as the output.
Great! Let’s run it. Here is an example output:
1
2
3
4
5
6
7
8
9
10
cats .traverse(f)
Converting [humongous]...
Converted [humongous] into [HUMONGOUS]
Converting [blue]...
Converted [blue] into [BLUE]
Converting [fluffy]...
Converted [fluffy] into [FLUFFY]
Converting [monster]...
Converted [monster] into [MONSTER]
results = List(HUMONGOUS, BLUE, FLUFFY, MONSTER)
It works well and the result is correct, but the order of operations is counterintuitive. Because we are using Futures, we expect that we’ll make use of the CPU and run the heavy computations in parallel. This didn’t happen here. Instead, each operation was run sequentially.
Before explaining why, let’s take one more step. Remember this?
Moreover,
.traversecan be implemented via.sequence..traverse(f)is the same thing as.map(f).sequence.
Let’s use this property. Here’s the modified code:
1
2
3
4
5
def runCatsMapSequence() = {
println("\ncats .map(f).sequence")
val results = entities.map(heavyComputation).sequence
println(s"results = ${Await.result(results, 15.seconds)}")
}
Running it should yield the same result, shouldn’t it? Well, here’s the kicker:
1
2
3
4
5
6
7
8
9
10
cats .map(f).sequence
Converting [humongous]...
Converting [blue]...
Converting [fluffy]...
Converting [monster]...
Converted [blue] into [BLUE]
Converted [fluffy] into [FLUFFY]
Converted [monster] into [MONSTER]
Converted [humongous] into [HUMONGOUS]
results = List(HUMONGOUS, BLUE, FLUFFY, MONSTER)
It turns out that this time the computations were run in parallel.
Where’s the catch?
There are 2 main contributors to the behavior we observe above:
.traversedoesn’t guarantee the execution order.- The
Futureis evaluated eagerly.
Because of the first point, we cannot be sure when the Futures will be executed. They could be run in parallel, but unfortunately for us, they were evaluated sequentially.
Due to the second point, we observe parallel execution when .traverse is replaced with .map(f).sequence. Right after .map(f) is applied, the Futures are started. Thus, .sequence operates on already started computations and just gathers the results. As we see in the outputs, cats’ .traverse isn’t implemented as .map(f).sequence because the outputs of the snippets above are different.
The code above was written using cats 2.10. The behavior of
.traverseforFutures was first changed in a minor cats version. After that,Futureusages with cats were deprecated due to being error-prone, but there are no plans for removal.In 2.11 the behavior has changed again. This might happen in the future as well.
Now, we learned the hard way why using Futures with Cats is generally discouraged. The result was unexpected and nothing warned us about it (well, except for the documentation in the source code that we didn’t read). What’s more, we discovered it only because we went the extra mile to investigate it in depth. Since the outputs are the same, this issue could have been running in our codebase for months or even years unnoticed (make sure to check your codebase!), degrading the performance of our system.
The question is: can we do better?
Standard library to the rescue
It turns out that we don’t really have to use cats - Scala’s standard library can help us here. Future companion object already contains .traverse method that we can utilize. Let’s slightly modify our code:
1
2
3
4
5
def runStdLibTraverse() = {
println("\nstandard library .traverse(f)")
val results = Future.traverse(entities)(heavyComputation)
println(s"results = ${Await.result(results, 15.seconds)}")
}
Here is the output:
1
2
3
4
5
6
7
8
9
10
standard library .traverse(f)
Converting [humongous]...
Converting [blue]...
Converting [fluffy]...
Converting [monster]...
Converted [blue] into [BLUE]
Converted [fluffy] into [FLUFFY]
Converted [monster] into [MONSTER]
Converted [humongous] into [HUMONGOUS]
results = List(HUMONGOUS, BLUE, FLUFFY, MONSTER)
The computations are run in parallel, that’s exactly what we wanted!
What’s more, Future also has a .sequence method. In this case, Future.traverse(collection)(f) is the same as Future.sequence(collection.map(f)). Of course, the syntax is not that tidy, but it’s a minor inconvenience considering the optimized code it provides. We can always write the extension methods ourselves if needed.
Would IO help?
Okay, after we proved that using standard library in this case is more intuitive, you might be wondering whether using Cats Effect’s IO instead would be better. I would say that the most valuable property of IO in this case is its predictable behavior.
Here’s the IO version of our heavyComputation (pure this time!):
1
2
3
4
5
6
7
def heavyComputationIO(entity: Entity): IO[Result] =
for {
_ <- IO(println(s"Converting [$entity]..."))
result = entity.toUpperCase
_ <- IO.sleep(100.millis * entity.size) // Pretend it's really heavy
_ <- IO(println(s"Converted [$entity] into [$result]"))
} yield result
It’s very similar to what we wrote previously, but uses IO to enclose println calls and IO.sleep instead of Thread.sleep.
Now, if we run it with .traverse:
1
2
3
4
5
def runCatsIOTraverse() = {
println("\nIO cats .traverse(f)")
val results = entities.traverse(heavyComputationIO)
println(s"results = ${results.unsafeRunSync()}")
}
We get…
1
2
3
4
5
6
7
8
9
10
IO cats .traverse(f)
Converting [humongous]...
Converted [humongous] into [HUMONGOUS]
Converting [blue]...
Converted [blue] into [BLUE]
Converting [fluffy]...
Converted [fluffy] into [FLUFFY]
Converting [monster]...
Converted [monster] into [MONSTER]
results = List(HUMONGOUS, BLUE, FLUFFY, MONSTER)
…a sequential execution. So nothing has changed compared to the use with Future, has it? Moreover, if we dig deeper, we’ll find that if .traverse is replaced with .map(f).sequence, it also won’t run in parallel!
1
2
3
4
5
def runCatsIOMapSequence() = {
println("\nIO cats .map(f).sequence")
val results = entities.map(heavyComputationIO).sequence
println(s"results = ${results.unsafeRunSync()}")
}
1
2
3
4
5
6
7
8
9
10
IO cats .map(f).sequence
Converting [humongous]...
Converted [humongous] into [HUMONGOUS]
Converting [blue]...
Converted [blue] into [BLUE]
Converting [fluffy]...
Converted [fluffy] into [FLUFFY]
Converting [monster]...
Converted [monster] into [MONSTER]
results = List(HUMONGOUS, BLUE, FLUFFY, MONSTER)
Is the sequential execution the predictability that I mentioned? Not really. With IO, we have to tell the runtime that we want to perform the computation in parallel. Instead of using .traverse or .sequence, we have to use .parTraverse or .parSequence.
Here is our example with .parTraverse:
1
2
3
4
5
def runCatsIOParTraverse() = {
println("\nIO cats .parTraverse(f)")
val results = entities.parTraverse(heavyComputationIO)
println(s"results = ${results.unsafeRunSync()}")
}
If we check the output, it finally runs in parallel:
1
2
3
4
5
6
7
8
9
10
IO cats .parTraverse(f)
Converting [humongous]...
Converting [blue]...
Converting [fluffy]...
Converting [monster]...
Converted [blue] into [BLUE]
Converted [fluffy] into [FLUFFY]
Converted [monster] into [MONSTER]
Converted [humongous] into [HUMONGOUS]
results = List(HUMONGOUS, BLUE, FLUFFY, MONSTER)
To add more to it, we even have .parTraverseN which allows us to limit the maximum number of parallel computations.
Finer control over the execution of the
Future.traverseis also possible but requires a bit more effort. It could be achieved by configuring the implicitExecutionContextbeing used.
In the snippet below, the maximum is set to 2:
1
2
3
4
5
def runCatsIOParTraverseN() = {
println("\nIO cats .parTraverseN(2)(f)")
val results = entities.parTraverseN(2)(heavyComputationIO)
println(s"results = ${results.unsafeRunSync()}")
}
1
2
3
4
5
6
7
8
9
10
IO cats .parTraverseN(2)(f)
Converting [fluffy]...
Converting [monster]...
Converted [fluffy] into [FLUFFY]
Converting [humongous]...
Converted [monster] into [MONSTER]
Converting [blue]...
Converted [blue] into [BLUE]
Converted [humongous] into [HUMONGOUS]
results = List(HUMONGOUS, BLUE, FLUFFY, MONSTER)
As you see in the output above:
- Computations for
fluffyandmonsterare started. - Computation for
fluffycompletes, allowing the computation forhumongousto start. - Computation for
monstercompletes, allowing the computation forblueto start. - Computations for
blueandmonstercomplete.
We could achieve similar results with .parSequenceN.
The fact that IO requires being explicit and gives us tools for finer control makes it superior. However, not every use case requires IO, and not every application contains Cats Effect. It’s up to you to decide which one fits your use case. Remember to be pragmatic 😉
You might ask why we cannot just use
.parTraverseor.parTraverseNtogether with aFuture. It turns out thatFuturedoesn’t contain an instance for Parallel typeclass defined, which is required to use the.par...methods.
Summary
Well, it turned out to be quite a lengthy exploration for what seemed like a simple concept. Hopefully, now you see why blending impure code with cats might lead to unexpected outcomes. But with careful attention, it’s possible to navigate these challenges. After all, there’s no functional police waiting to catch us in the act.
In my view, it’s crucial to remember that the primary goal of our code is to solve problems and deliver value. Being pragmatic allows us to strike a balance between adhering to best practices and delivering features quickly. It’s evident that managing functional overhead can be complex, which might explain the trend toward direct style.
You can find the code from the snippets on Scastie: https://scastie.scala-lang.org/rWmONXkjR32iaS7Bd3YKlw