Adding transactions to Scala repositories
Not that long ago, I had to review a piece of code that worked like this:
- receive an HTTP request
- split the body into 5 parts
- save each part in a dedicated repository which writes to Postgres tables under the hood
At first, it seemed quite easy. Then we found out that we need to add SQL transactions to the repositories to avoid concurrency issues. That turned out to be a pretty complex task. Not because we needed to add transactions, but because we wanted to have code that is easy to maintain and doesn’t depend on the fact that we are using SQL tables beneath.
In this post, I want to show how to deal with transactions across the repositories and highlight what problems you may encounter. I’ll present my approach to the solution from a cumbersome design to a more robust solution step by step.

Example context
Suppose we wanted to build a part of a bank account management system. Our users can check their balances and add funds. Additionally, each time they deposit some money they get a kind of loyalty points. Of course, this is just a minimal fragment of the functionalities we could provide in such a system.
Here is our table schema:
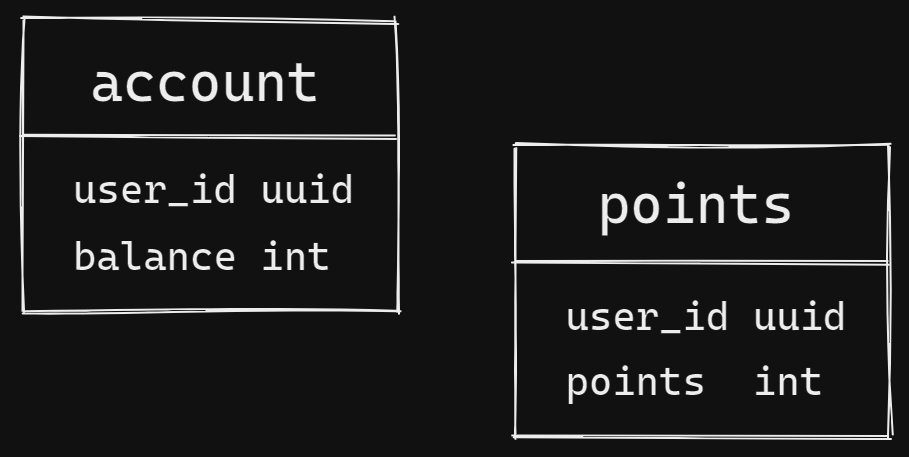
usertable is not that relevant here. Let’s assume that it is defined somewhere and contains all fields that a user entity may require.
The components that we want to have are:
- abstract repositories for account and points
- concrete implementations of our repositories
- a service that encloses the main logic of adding funds and awarding loyalty points
Main goals of the final solution
The requirements that we want our code to fulfill are:
- a transactional character of operations execution
- the services determine the boundaries of the transactions they execute
- the services are easy to test with repository mocks
- repositories don’t have a predefined effect (eg.
IO) in the method return types - abstractions do not depend on the implementations, ie. repositories don’t use types that are specific to the classes that implement them - this will become clear later
I don’t cover the isolation levels in this post. You may still encounter concurrency issues without a proper isolation level set on the database or transaction level.
IO repositories
Let’s start with the initial, clumsy definition of our repositories that we will refactor later. The account repository looks like this:
1
2
3
4
trait AccountRepository {
def getBalance(userId: UUID): IO[Option[Int]]
def addFunds(userId: UUID, amountToAdd: Int): IO[Unit]
}
We’ve used IO from Cats Effect as an effect. The points repository is quite similar:
1
2
3
4
trait PointsRepository {
def getPoints(userId: UUID): IO[Option[Int]]
def incrementPoints(userId: UUID): IO[Unit]
}
The next thing is a service that exposes a method for adding funds, which both increases the balance and increments the loyalty points.
1
2
3
4
5
6
7
8
9
10
class AccountManagementService(
accountRepository: AccountRepository,
pointsRepository: PointsRepository
) {
def addFunds(userId: UUID, amountToAdd: Int): IO[Unit] =
for {
_ <- accountRepository.addFunds(userId, amountToAdd)
_ <- pointsRepository.incrementPoints(userId)
} yield ()
}
The last missing piece is the implementation of our repositories. We’ll use a PostgreSQL database and queries written in doobie. The first Postgres repository is the one for accounts:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
class PostgresAccountRepository(xa: Transactor[IO]) extends AccountRepository {
override def getBalance(userId: UUID): IO[Option[Int]] =
getBalanceConnectionIO(userId).transact(xa)
private def getBalanceConnectionIO(userId: UUID): ConnectionIO[Option[Int]] =
// sql
override def addFunds(userId: UUID, amountToAdd: Int): IO[Unit] = {
for {
currentBalance <- getBalanceConnectionIO(userId)
newBalance = currentBalance.getOrElse(0) + amountToAdd
_ <- setBalanceConnectionIO(userId, newBalance)
} yield ()
}.transact(xa)
private def setBalanceConnectionIO(userId: UUID, balance: Int): ConnectionIO[Int] =
// sql
}
Here we’ve used a Transactor[IO] from doobie that allows converting a ConnectionIO produced by doobie SQL queries to an IO. The repository for points is analogous:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
class PostgresPointsRepository(xa: Transactor[IO]) extends PointsRepository {
override def getPoints(userId: UUID): IO[Option[Int]] =
getPointsConnectionIO(userId).transact(xa)
private def getPointsConnectionIO(userId: UUID): ConnectionIO[Option[Int]] =
// sql
override def incrementPoints(userId: UUID): IO[Unit] = {
for {
currentPoints <- getPointsConnectionIO(userId)
newPoints = currentPoints.getOrElse(0) + 1
_ <- setPointsConnectionIO(userId, newPoints)
} yield ()
}.transact(xa)
private def setPointsConnectionIO(userId: UUID, points: Int): ConnectionIO[Int] =
// sql
}
Now as we have all elements needed, we can construct our service:
1
2
3
4
5
6
7
8
9
10
val xa = Transactor.fromDriverManager[IO](
driver = "org.postgresql.Driver",
url = "jdbc:postgresql://localhost:5432/postgres",
user = "postgres",
pass = "example"
)
val accountManagementService = new AccountManagementService(
accountRepository = new PostgresAccountRepository(xa),
pointsRepository = new PostgresPointsRepository(xa)
)
The service can be used to add some funds to a user account. This can be written as simply as:
1
2
val userId = // uuid
accountManagementService.addFunds(userId, 10)
The code above adds 10 to the user balance. Assuming that we are starting with 0 funds and 0 points, we should end up with an account balance of 10 and 1 loyalty point.
The problem with the IO approach
The main problem with the IO is that the operations in the repositories are fully independent. This means that we may add funds, lose connection and end up not rewarding the user with his loyalty points. It is better to handle the operation as a whole.
ConnectionIO repositories
Let’s improve the repositories and add transactions across them. As we are using doobie, we’ll make use of ConnectionIO. Each executed ConnectionIO is a bounded transaction.
The account repository now looks like this:
1
2
3
4
trait AccountRepository {
def getBalance(userId: UUID): ConnectionIO[Option[Int]]
def addFunds(userId: UUID, amountToAdd: Int): ConnectionIO[Unit]
}
The points repository is again defined similarly:
1
2
3
4
trait PointsRepository {
def getPoints(userId: UUID): ConnectionIO[Option[Int]]
def incrementPoints(userId: UUID): ConnectionIO[Unit]
}
To adjust the Postgres implementations to the above signatures, we just have to remove .transact(xa) from the methods and xa itself as it is no longer used.
So where xa goes now? It has to go to the service which will execute the transaction:
1
2
3
4
5
6
7
8
9
10
11
12
class AccountManagementService(
accountRepository: AccountRepository,
pointsRepository: PointsRepository
)(xa: Transactor[IO]) {
def addFunds(userId: UUID, amountToAdd: Int): IO[Unit] = {
for {
_ <- accountRepository.addFunds(userId, amountToAdd)
_ <- pointsRepository.incrementPoints(userId)
} yield ()
}.transact(xa)
}
Great! We have transactions and the service decides where to put the transaction boundaries.
“Leave transaction control to the client” is one of the principles of designing repositories in Domain-Driven Design.
So where is the catch?
It may not be obvious at the first glance, but we’ve constrained ourselves. Now both the repositories and the service depend on classes from doobie - ConnectionIO and Transactor. What if we wanted to move from doobie to Slick? How to easily mock a Transactor in tests?
Well, mocking a
Transactoris doable but pretty obscure - example here.
If we want to make our code cleaner, we have to somehow remove doobie dependencies while maintaining the same functionalities.
Higher kinded types to the rescue
Getting rid of the ConnectionIOs from the repositories is quite simple. We can just replace each reference to it with an F which is a higher kinded type. This way we end up with:
1
2
3
4
trait AccountRepository[F[_]] {
def getBalance(userId: UUID): F[Option[Int]]
def addFunds(userId: UUID, amountToAdd: Int): F[Unit]
}
and
1
2
3
4
trait PointsRepository[F[_]] {
def getPoints(userId: UUID): F[Option[Int]]
def incrementPoints(userId: UUID): F[Unit]
}
Now we can use any effect, including IO, or even wrap the result in a Future.
Let’s move to a more (but not that much!) complicated aspect of the code, which is the service. As our repositories now require a type parameter, we have to give it to them. We don’t want to use ConnectionIO here too, so we again introduce an F to the class:
1
2
3
4
class AccountManagementService[F[_]: Monad](
accountRepository: AccountRepository[F],
pointsRepository: PointsRepository[F]
)(xa: Transactor[IO])
Note that we’ve also added a Monad context bound as for comprehensions are using flatMap and map on F.
Okay, we are getting closer. Now, how can we get rid of that Transactor? First, let’s think about what purpose it serves. It is used as an argument in .transact(xa) calls and transforms a ConnectionIO into an IO. So the Transactor is just a transformer which can be denoted as ConnectionIO ~> IO. Does it remind you of something? Yes, it’s just a FunctionK.
With this knowledge, we can also choose whether we want to stick to an IO as our output effect or also parametrize it. My choice is to be more flexible, so we’ll introduce a higher kinded G.
The service now looks like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
class AccountManagementService[F[_]: Monad, G[_]](
accountRepository: AccountRepository[F],
pointsRepository: PointsRepository[F]
)(implicit transactor: F ~> G) {
def addFunds(userId: UUID, amountToAdd: Int): G[Unit] =
transactor {
for {
_ <- accountRepository.addFunds(userId, amountToAdd)
_ <- pointsRepository.incrementPoints(userId)
} yield ()
}
}
I made the transactor implicit for convenience. When having multiple services or tests, the transactor will probably look the same everywhere so making it implicit unclutters the code. The transactor is a FunctionK from F to G, where G is the output effect of the transaction. Executing a transaction enclosed in F is as simple as calling transactor#apply method.
The last piece that we need is a transactor instance and a slight modification in the service definition:
1
2
3
4
5
6
7
8
9
implicit val transactor: ConnectionIO ~> IO = new (ConnectionIO ~> IO) {
def apply[A](connectionIO: ConnectionIO[A]): IO[A] = connectionIO.transact(xa)
}
val accountManagementService: AccountManagementService[ConnectionIO, IO] =
new AccountManagementService(
accountRepository = new PostgresAccountRepository(),
pointsRepository = new PostgresPointsRepository()
)
And we are done! We have repositories that do not depend on ConnectionIO and a service that decides on the transaction boundaries. The only things that depend on doobie classes are concrete Postgres implementations of the repositories and the implicit transactor which executes the transactions.
As doobie is built on top of cats,
ConnectionIOalready has aMonadinstance defined, which satisfiesF[_]: Monadcontext bound of the service. If you are using something else, you may have to define the instance yourself.
This allows us to swap the data access layer without touching the repositories or service code at all. Speaking of the tests…
Testing the service
For free, we get all the benefits of using higher kinded types so easy mocking and synchronous tests for classes that most often have an asynchronous nature. Let’s take a look at an example test implemented using ScalaTest and ScalaMock:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
"addFunds" when {
"given an user ID and an amount to add" should {
"call the account repository with the amount and increment points in the points repository" in {
val userId = UUID.randomUUID()
val amountToAdd = 123
val accountRepository = mock[AccountRepository[Id]]
(accountRepository.addFunds _).expects(userId, amountToAdd).returning(())
val pointsRepository = mock[PointsRepository[Id]]
(pointsRepository.incrementPoints _).expects(userId).returning(())
implicit val transactor: Id ~> Id = FunctionK.id
val accountManagementService = new AccountManagementService(accountRepository, pointsRepository)
accountManagementService.addFunds(userId, amountToAdd)
}
}
}
Here we’re using cats identity monad Id which is just a pure value. We can use it as our transactional type and the output effect. This allows easy synchronous tests for our service.
As a bonus, you also get the ability to define synchronous in-memory repositories using
Idif you need them.
Summary
In this post, we’ve implemented a service that uses two repositories to make a transactional operation. The service has full control over the boundaries of the executed transactions. It is also easy to test synchronously using mocks. Both repositories and the service do not depend on types from doobie and are fully abstract.
For me, it seems to be a pretty common pattern so my advice would be to use it whenever you see the opportunity to do so. Additional higher kinded types are worth the effort and the benefits are significant, especially in bigger projects that evolve quickly.
Thank you for reading and feel free to share your thoughts on this topic!
The full code from this post can be found here.